[ 목차 ]
0. 함수란
➯ 단일 행 함수 vs 복수 행 함수
1. 산술 함수
2. 문자열 함수
3. 날짜 및 시간 함수
4. 집계 함수
5. 제어 흐름 함수
6. 형 변환 함수
0. 함수란?

단일 행 함수(Single-Row Functions)
- 단일 행 함수는 하나의 입력 값에 대해 하나의 결과를 반환하는 함수다.
- 즉, 하나의 행 데이터가 1:1로 치환되어 반환된다는 뜻이다.
- 주로 데이터 변환이나 조작에 사용된다.
- 보통 SELECT, WHERE, ORDER BY절에서 사용된다.
- 중첩이 가능하다.
SELECT UPPER(name), SUBSTRING(name, 1, 3)
FROM EMPLOYEE
WHERE LENGTH(name) > 5
ORDER BY LOWER(name);
복수 행 함수(Multi-Row Functions)
- 복수 행 함수는 여러 행의 데이터를 하나의 결괏값으로 반환하는 함수다.
- 주로 합계, 평균, 개수, 최대/최소 값 등을 계산하는 데 사용된다.
➯ 이런 집계를 목적으로 하는 함수들은 GROUP BY와 잘 어울려져 사용된다. - 보통 SELECT, HAVING절에서 사용된다.
SELECT department, AVG(salary) AS average_salary
FROM EMPLOYEE
GROUP BY department
HAVING AVG(salary) > 3000
ORDER BY average_salary DESC;
1. 산술 함수(Arithmetic Functions)
• ABS(x): x의 절대값 반환
SELECT ABS(-15); -- 결과: 15
• CEIL(x): x보다 크거나 같은 최소 정수 반환
SELECT CEIL(5.3); -- 결과: 6
• FLOOR(x): x보다 작거나 같은 최대 정수 반환
SELECT FLOOR(1.8); -- 결과: 1
• MOD(x, y): x를 y로 나눈 나머지 반환
SELECT MOD(9, 2); -- 결과: 1
• ROUND(x, d): x를 소수점 d자리까지 반올림
SELECT ROUND(2.71828, 2); -- 결과: 2.72
• TRUNCATE(x, d): x를 지정한 소수점 d자리까지 자르고 남은 부분을 버린 값 반환
(d가 음수일 경우, 정수자리를 자른다)
SELECT TRUNCATE(1234.5678, 2); -- 결과: 1234.56
SELECT TRUNCATE(1234.5678, 1); -- 결과: 1234.5
SELECT TRUNCATE(1234.5678, 0); -- 결과: 1234
SELECT TRUNCATE(1234.5678, -1); -- 결과: 1230
SELECT TRUNCATE(1234.5678, -2); -- 결과: 1200
• SQRT(x): x의 제곱근 값 반환
SELECT SQRT(100); -- 결과: 10
• POW(x, n): x를 n 제곱한 값 반환
SELECT POW(5, 3); -- 결과: 125
• SIGN(x): x가 양수면 1, 음수면 -1 반환
SELECT SIGN(100); -- 결과: 1
SELECT SIGN(-100); -- 결과: -1
• RAND(): 0 ~ 1 사이의 랜덤값 반환
SELECT RAND(); -- 결과: 0 ~ 1 사이의 랜덤값 ex) 0.7664805947
SELECT RAND() * 100; -- 결과: 0 ~ 100 사이의 랜덤값 ex) 60.3688671816
SELECT FLOOR(RAND() * 100) + 1; -- 결과: 1 ~ 100 사이의 랜덤 정수값 ex) 47
• BIN(x), OCT(x), HEX(x): 각각 x의 2진수, 8진수, 16진수 값을 반환
SELECT BIN(10); -- 결과: '1010'
SELECT OCT(10); -- 결과: '12'
SELECT HEX(10); -- 결과: 'A'
2. 문자열 함수(String Functions)
※ MySQL에서 문자열의 첫 문자는 0번째가 아니라 1번째로 시작한다.
• LOWER(s), UPPER(s) : 문자열을 대/소문자로 치환하는 함수
SELECT LOWER('Love wins all'); -- 결과: 'love wins all'
SELECT UPPER('Love wins all'); -- 결과: 'LOVE WINS ALL'
• CONCAT(s), CONCAT_WS(s) : 두 개 이상의 문자열을 하나로 결합하는 함수
SELECT CONCAT('누가 내 머리에 ', '똥쌌어?'); -- 결과: '누가 내 머리에 똥쌌어?'
# CONCAT_WS: 특정 구분자를 사용해 문자 결합 가능
SELECT CONCAT_WS('/', '2024', '10','03'); -- 결과: '2024/10/03'
• LENGTH(s), CHAR_LENGTH(s): 문자열의 바이트 수 반환, 문자열의 길이 반환
# 바이트 수 반환
SELECT LENGTH(1) FROM DUAL; -- 결과: 1
SELECT LENGTH('A') FROM DUAL; -- 결과: 1
SELECT LENGTH('가') FROM DUAL; -- 결과: 3
SELECT LENGTH('가지 볶음') FROM DUAL; -- 결과: 13
# 길이 반환
SELECT CHAR_LENGTH(1) FROM DUAL; -- 결과: 1
SELECT CHAR_LENGTH('A') FROM DUAL; -- 결과: 1
SELECT CHAR_LENGTH('가') FROM DUAL; -- 결과: 1
SELECT CHAR_LENGTH('가지 볶음') FROM DUAL; -- 결과: 5※ 영어는 한 글자에 1byte, 한글은 한 글자에 3byte다.
• SUBSTRING(s, pos, [len]): 문자열 s에서 pos 위치부터 len 길이만큼 잘라낸 문자열을 반환
SELECT SUBSTRING('여기 물냉면 하나랑 만두 하나 주세요.', 12, 5);
-- 결과: '만두 하나'
# len 값을 입력하지 않았다면, 끝까지 자르라는 것
SELECT SUBSTRING('여기 물냉면 하나랑 만두 하나 주세요.', 12);
-- 결과: '만두 하나 주세요.'
# SUBSTR()로 써도 된다.
SELECT SUBSTR('여기 물냉면 하나랑 만두 하나 주세요.', 12);
-- 결과: '만두 하나 주세요.'# [활용 예시]
SELECT name, SUBSTR(name, 1, 1) as 성
FROM EMPLOYEE;
SELECT name, SUBSTR(name, 2) as 이름
FROM EMPLOYEE;
• SUBSTRING_INDEX(s, d, c): 문자열 s를 특정 구분자 d를 기준으로 잘라내어 원하는 부분을 반환
c : 구분자가 등장하는 횟수를 기준으로 반환할 부분 지정
→ c > 0: 왼쪽에서부터 구분자를 세고 그 부분까지 반환
→ c < 0: 오른쪽에서부터 구분자를 세고 그 부분까지 반환
SELECT SUBSTRING_INDEX('물냉면, 비빔냉면, 군만두', ',', 2); -- 결과: '물냉면, 비빔냉면'
SELECT SUBSTRING_INDEX('userID@naver.com', '@', 1); -- 결과: 'userID'
SELECT SUBSTRING_INDEX('userID@naver.com', '@', -1); -- 결과: 'naver.com'
• INSTR(s, sub_s): 문자열 s에서 내가 찾고자 하는 문자나 단어가 처음 등장하는 위치 반환
SELECT INSTR('여기 물냉면 하나랑 만두 하나 주세요.', '만두'); -- 결과: 12
# 공백도 검색이 가능하다.
SELECT INSTR('여기 물냉면 하나랑 만두 하나 주세요.', ' '); -- 결과: 3
• LEFT, RIGHT(s, len) : 문자열 s에서 왼쪽 또는 오른쪽 길이 len만큼을 추출
SELECT LEFT("abcde", 3); -- 결과: 'abc'
SELECT RIGHT("abcde", 3); -- 결과: 'cde'
• MID(s, pos, len) : 문자열 s의 특정 시작점 pos에서 길이 len만큼 추출
SELECT MID("가나다라마바사", 4, 2); -- 결과: '라마'
• REPLACE(s, old_s, new_s): 문자열 s에서 old_s를 new_s로 대체
SELECT REPLACE('여기 물냉면 하나랑 만두 하나 주세요.', '물냉면', '비빔냉면');
-- 결과: '여기 비빔냉면 하나랑 만두 하나 주세요.'
• TRIM([[LEADING | TRAILING | BOTH] [remstr] FROM] s): 앞뒤 공백이나 특정 문자 제거
→ LEADING: 문자열의 앞쪽에서만 문자를 제거
→ TRAILING: 문자열의 뒤쪽에서만 문자를 제거
→ BOTH: 문자열의 양쪽에서 문자를 제거 (기본값)
→ remstr: 제거할 특정 문자로 생략하면 공백을 제거
→ s: 원본 문자열
SELECT TRIM(' 가지 볶음 '); -- 결과: '가지 복음'
SELECT TRIM('ㅌ' FROM 'ㅌㅌ가지 볶음ㅌㅌ'); -- 결과: '가지 볶음'
SELECT TRIM(BOTH 'ㅌ' FROM 'ㅌㅌ가지 볶음ㅌㅌ'); -- 결과: '가지 볶음'
SELECT TRIM(TRAILING 'ㅌ' FROM 'ㅌㅌ가지 볶음ㅌㅌ'); -- 결과: 'ㅌㅌ가지 볶음'
SELECT TRIM(LEADING 'ㅌ' FROM 'ㅌㅌ가지 볶음ㅌㅌ'); -- 결과: '가지 볶음ㅌㅌ'
• SPACE(len): 길이만큼 공백 반환
SELECT CONCAT('★★★★', SPACE(3), '★★★★'); -- 결과: '★★★★ ★★★★'
• LPAD, RPAD(s, len, pad_s) : 문자열s를 특정 길이 len까지 왼쪽 또는 오른쪽으로 특정 문자 pad_s를 추가하여 패딩(채우기)를 하는 함수
SELECT LPAD('abc', 5, '0'); -- 결과: '00abc'
SELECT RPAD('abc', 5, '0'); -- 결과: 'abc00'
• REVERSE(s): 문자열 s를 거꾸로 반환
SELECT REVERSE('123456789'); -- 결과: '987654321'
• REPEAT(s, len): 문자열 s를 주어진 횟수 len만큼 반복
SELECT REPEAT('치즈버거 ', 3); -- 결과: '치즈버거 치즈버거 치즈버거 '
• LOCATE(sub_s, s, [pos]): 특정 문자열 sub_s를 문자열 s에서 발견한 첫 번째 위치 반환
SELECT LOCATE('가지', '가지 볶음'); -- 결과: 1
# 같은 기능을 가진 다른 함수
SELECT POSITION('가지' IN '가지 볶음'); -- 결과: 1
SELECT INSTR('가지 볶음', '가지'); -- 결과: 1
# 시작지점을 지정하는 것은 Locate에서만 가능!
SELECT LOCATE('가지', '가지 볶음과 가지 튀김', 2); -- 결과: 8
• FORMAT(n, d, [local]): 숫자 n을 지정된 형식에 맞게 포맷팅
(주로 숫자에 천 단위 구분 기호 추가나 소수점 자리를 지정하여 숫자를 가독성 있게 표시하기 위해 사용)
d: 표시할 소수점 이하 자릿수
SELECT FORMAT(1234567.89, 2); -- 결과: '1,234,567.89'
SELECT FORMAT(1234567.89, 0); -- 결과: '1,234,567'
# local로 지역 설정도 가능하다
SELECT FORMAT(1234567.89, 2, 'de_DE'); -- 결과: '1.234.567,89'
3. 날짜 및 시간 함수(Date & Time Functions)
• 🔽 현재 날짜 또는 시간을 반환하는 함수 모음
# 현재 날짜를 '년-월-일'로 반환
SELECT CURDATE(); -- 결과: '2024-10-03'
# 현재 시간을 HH:MM:SS로 반환
SELECT CURTIME(); -- 결과: '16:19:08'
# 현재 날짜 및 시간 반환
SELECT CURRENT_TIMESTAMP(); -- 결과: '2024-10-03 16:19:18'
SELECT NOW(); -- 결과: '2024-10-03 16:19:18'
SELECT SYSDATE(); -- 결과: '2024-10-03 16:19:18'
📝CURRENT_TIMESTAMP VS NOW() VS SYSDATE()
SELECT
CURRENT_TIMESTAMP,
NOW(),
SYSDATE(),
SLEEP(5),
CURRENT_TIMESTAMP,
NOW(),
SYSDATE();
ㆍCURRENT_TIMESTAMP: 쿼리 시작 시점의 날짜와 시간을 반환
➯ 주로 테이블을 생성할 때 default 값 설정으로 사용
ㆍNOW(): 쿼리 시작 시점의 날짜와 시간을 반환
➯ 현재 시각 참조나 데이터 삽입 시 사용
ㆍSYSDATE(): 쿼리 호출 시점의 실제 날짜와 시간 반환
➯ 시간 차이를 고려해야할 때 사용
• 🔽특정 날짜나 시간의 단위를 반환하는 함수 모음
# 날짜의 '연도' 반환
SELECT YEAR('2024-10-03'); -- 결과: 2024
# 날짜의 '월' 반환
SELECT MONTH('2024-10-03'); -- 결과: 10
# 날짜의 '일' 반환
SELECT DAYOFMONTH('2024-10-03'); -- 결과: 3
SELECT DAY('2024-10-03'); -- 결과: 3
# '시간' 반환
SELECT HOUR('2024-10-03 16:19:18'); -- 결과: 16
SELECT HOUR('16:19:18'); -- 결과: 16
# '분' 반환
SELECT MINUTE('2024-10-03 16:19:18'); -- 결과: 19
SELECT MINUTE('16:19:18'); -- 결과: 19
# '초' 반환
SELECT SECOND('2024-10-03 16:19:18'); -- 결과: 18
SELECT SECOND('16:19:18'); -- 결과: 18
• 🔽날짜를 기준으로 차이를 더하거나 빼는 함수 모음
# 차이만큼 더한 값 반환
SELECT ADDDATE('2024-12-31', INTERVAL 10 DAY); -- 결과: '2025-01-10'
SELECT ADDDATE('2024-12-31', INTERVAL 1 MONTH); -- 결과: '2025-01-31'
# 차이만큼 뺀 값 반환
SELECT SUBDATE('2024-12-31', INTERVAL 10 DAY); -- 결과: '2024-12-21'
SELECT SUBDATE('2024-12-31', INTERVAL 1 MONTH); -- 결과: '2024-11-30'
• 🔽날짜 혹은 시간 차이를 반환하는 함수 모음
# 날짜 차이
SELECT DATEDIFF('2024-12-31', '2024-02-12'); -- 결과: 323
SELECT DATEDIFF('2024-02-12', '2024-12-31'); -- 결과: -323
# 시간 차이
SELECT TIMEDIFF('16:19:10', '08:40:50'); -- 결과: '07:38:20'
SELECT TIMEDIFF('08:40:50', '16:19:10'); -- 결과: '-07:38:20'
• MONTHNAME(date) : 해당 날짜의 월을 영어 이름으로 반환
SELECT MONTHNAME(NOW()); -- 결과: 'October'
• DATEOFWEEK(date): 해당 날짜의 요일을 숫자로 반환
SELECT DAYOFWEEK(NOW()); -- 결과: 5
• LASTDAY(date): 해당 날짜의 월의 마지막 날 반환
SELECT LAST_DAY('2024-02-01'); -- 결과: '2024-02-29'
• DAYOFYEAR(date): 1월 1일 기준 몇 일이 지났는 지를 반환
SELECT DAYOFYEAR(NOW()); -- 결과: 277
• TIME_TO_SEC(time): 시간을 초 단위로 반환
SELECT TIME_TO_SEC('12:00:00'); -- 결과: 43200
SELECT TIME_TO_SEC(CURTIME()); -- 결과: 63170
• DATE_FORMAT(date, format) : 해당 날짜를 지정된 형식으로 변환
SELECT DATE_FORMAT(NOW(), '%Y-%m-%d'); -- 결과: '2024-10-03'
SELECT DATE_FORMAT(NOW(), '%m/%d/%y'); -- 결과: '10/03/24'
SELECT DATE_FORMAT(NOW(), '%W, %D %M %Y'); -- 결과: 'Thursday, 3rd October 2024'
SELECT DATE_FORMAT(NOW(), '%M %Y'); -- 결과: 'October 2024'
SELECT DATE_FORMAT(NOW(), '%r'); -- 결과: '02:45:30 PM'
SELECT DATE_FORMAT(NOW(), '%T'); -- 결과: '14:45:30'
👉 사용 가능한 다른 코드 옵션
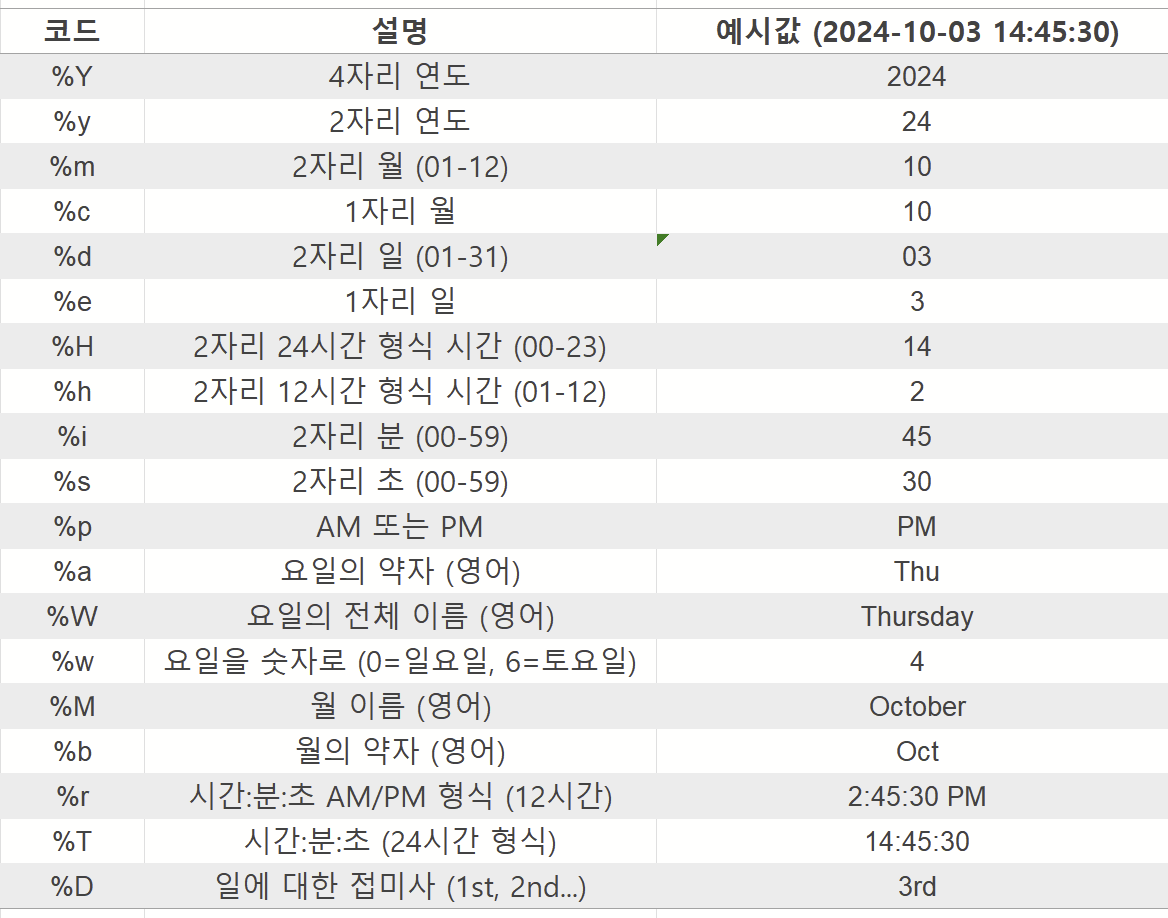
⏬더 많은 옵션은 아래 주소를 참고해 주세요.
MySQL :: MySQL 5.7 Reference Manual :: 12.7 Date and Time Functions
12.7 Date and Time Functions This section describes the functions that can be used to manipulate temporal values. See Section 11.2, “Date and Time Data Types”, for a description of the range of values each date and time type has and the valid formats
dev.mysql.com
4. 집계 함수(Aggregate Functions)
집계 함수가 복수 행 함수다.
• COUNT(column): 컬럼의 행의 수 반환
SELECT COUNT(*) FROM EMPLOYEE; -- 결과: 10
📝DISTINCT
- 중복값 없이 뽑고 싶다면 DISTINCT를 사용한다.
SELECT COUNT(singer) FROM POP_SONG_CHART; -- 결과: 10
SELECT COUNT(DISTINCT singer) FROM POP_SONG_CHART; -- 결과: 8
• SUM(column): 숫자 값을 가진 컬럼의 합계 반환
SELECT SUM(salary) FROM EMPLOYEE; -- 결과: 300,000,000
• AVG(column): 숫자 값을 가진 컬럼의 평균 반환
SELECT AVG(salary) FROM EMPLOYEE; -- 결과: 3,000,000
• MAX(column): 숫자 값을 가진 컬럼의 최댓값 반환
SELECT MAX(like_number) FROM POP_SONG_CHART; -- 결과: 2,705,300
• MIN(column): 숫자 값을 가진 컬럼의 최솟값 반환
SELECT MIN(like_number) FROM POP_SONG_CHART; --결과: 124,820
📝집계 함수에서 NULL값은 어떻게 취급되는가?
| 컬럼1 | 컬럼2 | |
| 1 | 10 | 20 |
| 2 | 20 | NULL |
ㆍ이렇게 두개의 숫자형 컬럼을 가진 테이블에 위와같이 데이터가 들어가 있다고 가정해보자.
Q 이때 각 컬럼에 대한 집계 함수의 값들은 어떻게 될까?
| column = 컬럼1 | column = 컬럼2 | |
| count(column) | 2 | 1 |
| sum(column) | 30 | 20 |
| avg(column) | 15 | 20 |
| max(column) | 20 | 20 |
| min(column) | 10 | 20 |
✔ NULL 값은 집계 함수에서 무시된다!
✔ COUNT(*)는 NULL값을 포함한 전채 행의 개수를 제니 헷갈리지 말도록 하자.
5. 제어 흐름 함수(Control Flow Functions)
• IF(expr, true_value, false_value): 조건에 따라 다른 값 반환
SELECT IF(price > 50000, 'High', 'Low') FROM PRODUCTS; --결과: 'High'
• CASE( WHEN value1 THEN result1 WHEN value2 THEN result2 ... ELSE else_result END):
다중 조건에 따른 값 반환
SELECT
CASE
WHEN price > 50000 THEN 'High'
WHEN price > 30000 THEN 'Medium'
ELSE 'Low'
END AS Quality
FROM PRODUCTS;
-- 결과: 'Medium'
• IFNULL(column, value): 컬럼의 값이 Null이라면 대체 값 value를 출력
SELECT IFNULL(data, '자료X') FROM BOOK_LIST; --결과: '자료X'
• COALESCE(value1, value2, ...): NULL이 아닌 첫 번째 인수 반환
SELECT COALESCE(NULL, NULL, '무화과', '복숭아'); --결과: '무화과'
6. 형 변환 함수(Conversion Functions)
• CAST(expr AS data_type): expr을 지정된 데이터 타입으로 변환
# 문자열을 날짜형으로 변환
SELECT CAST('2024-10-03' AS DATE);
# 문자열을 정수형으로 변환
SELECT CAST('123' AS UNSIGNED);
• CONVERT(expr, data_type): 데이터 타입 뿐만 아니라 문자열 인코딩 변환도 가능
# 문자열을 정수형으로 변환
SELECT CONVERT('456' , UNSIGNED);
# 문자열을 UTF-8 문자 집합으로 변환
SELECT CONVERT('abc' USING utf8mb4);
'데이터 분석 > MySQL' 카테고리의 다른 글
| MySQL 총 정리8: 테이블 조인(JOIN) (1) | 2024.10.07 |
|---|---|
| MySQL 총 정리7: GROUP BY와 HAVING (2) | 2024.10.05 |
| MySQL 총 정리5: ORDER BY로 데이터 정렬 (1) | 2024.10.02 |
| MySQL 총 정리4: 다양한 연산자로 필터링된 데이터 조회 (0) | 2024.09.30 |
| MySQL 총 정리3: SELECT으로 데이터 조회 (0) | 2024.09.28 |