'머신러닝은 최적화 과정이다' 라고 얘기할 정도로 머신러닝은 최적화(Optimization)를 굉장히 많이 사용한다.
고등학교 수학수업에서 배웠듯이, 최적화 문제에는 주로 미분을 사용하여 푼다. (미분을 통해 최소점과 최대점을 구할 수 있으니) 머신러닝과 딥러닝에서 최적화란 손실 함수(Loss Function)의 값을 최소화하는 파라미터를 구하는 과정이다. [손실함수란 예측값과 실제값의 차이를 비교하는 함수다]

해당 표는 6월 성적과 9월 성적을 토대로 수능 성적을 예측하는 문제에 대한 머신 러닝 모델의 예측값$(y ̂)$과 실제값$(y)$을 나타낸다. 6월 성적과 9월 성적 각각이 가지는 가중치는 동일하게 0.5 로 두었다. 이렇게 두 개의 파라미터의 값이 0.5 일시의 오차가 큰데, 이런 오차를 최소화하는 파라미터를 구하는 것이 최적화인것이다.
손실함수의 값이 최저점인 곳을 찾는다는 것은, 단순하게 미분해서 0이 되는 지점을 찾는다고 간단하게 생각해 볼 수가 있다. 하지만 생각처럼 그렇게 간단한 일이 아니다. 이유는...
1). 일단, 목적함수가 볼록한 형태일 경우는 드물다. 현실에서 대부분 비볼록한 형태를 띄고 있다.

- 목적함수가 볼록 함수(Convex Function)라면 어떤 지점에서 시작하더라도 최적값(손실함수가 최소로하는 점)에 도달할 수 있다. 하지만 비볼록 함수(Non-Convex Function)일 시, 시작점의 위치에 따라서 최적의 값이 달라지게 된다.

- 비볼록 함수의 경우 Local Minimum에 빠질 수 있다. (위처럼 함수 내 일정 구간에서의 최대값과 최솟값을 각각 Local Maximum, Local Minimum 이라 부르며 함수 전체에서의 최대값과 최솟값을 Global Maximum, Global Minimum 이라 부른다.) 또한, 최적의 값이라고 판단한 값이 Global 에서의 값인지, Local 값인지 구분할 수 없다는 한계가 존재한다.
2). Saddle Point (말안장점)

- 해당 그래프의 원점이 말안장점이다. (말의 안장과 비슷한 모양 위에 있는 점이라 해서 이런 이름이 붙여졌다고 한다.) 그림을 보면 알 수 있듯이, 미분이 0인 지점인 말안장점이 극값이 아니다. 보는 지점에 따라 최소값이 될수도 최대값이 될수도 있으니 기울기가 0이지만 최적점이 될 수가 없는 것이다.
아래 나올 내용은 책 Maschine Learning 기계학습 (한빛아카데미 | 오일석) 을 요약 및 정리한 글입니다.
미분에 의한 최적화
최적화 기법중에 하나로 경사 하강법(Gradient Descent)이 있는데, 이에 대해 얘기하기 앞서, 이해를 돕기 위해 미분에 의한 최적화를 간단한 예를 통해 알아보자.

위의 그림은 간단한 2차 다항식 함수의 1차, 2차 도함수를 나태난다. 임의의 점을 하나 정해 최저점을 찾아가보도록 하자. $x = 4$ 일 때의 1차 도함수 값은 $2 *4 - 4 = 4$로, 이 때 최저점은 이 점의 왼편에 있다. $x = 1$ 일 시엔, $2 *1 - 1 = - 2$로 최저점은 오른편에 있다. 즉, 도함수의 값이 +일 시 - 방향으로 가야 최저점을 만나며, 도함수의 값이 - 라면 + 방향으로 가야 최저점을 만난다는 것이다. 다시 말해 $-f'(x)$ 방향으로 가면 최저점을 찾을 수 있다는 사실이다.
조금 다르게 설명하자면...,
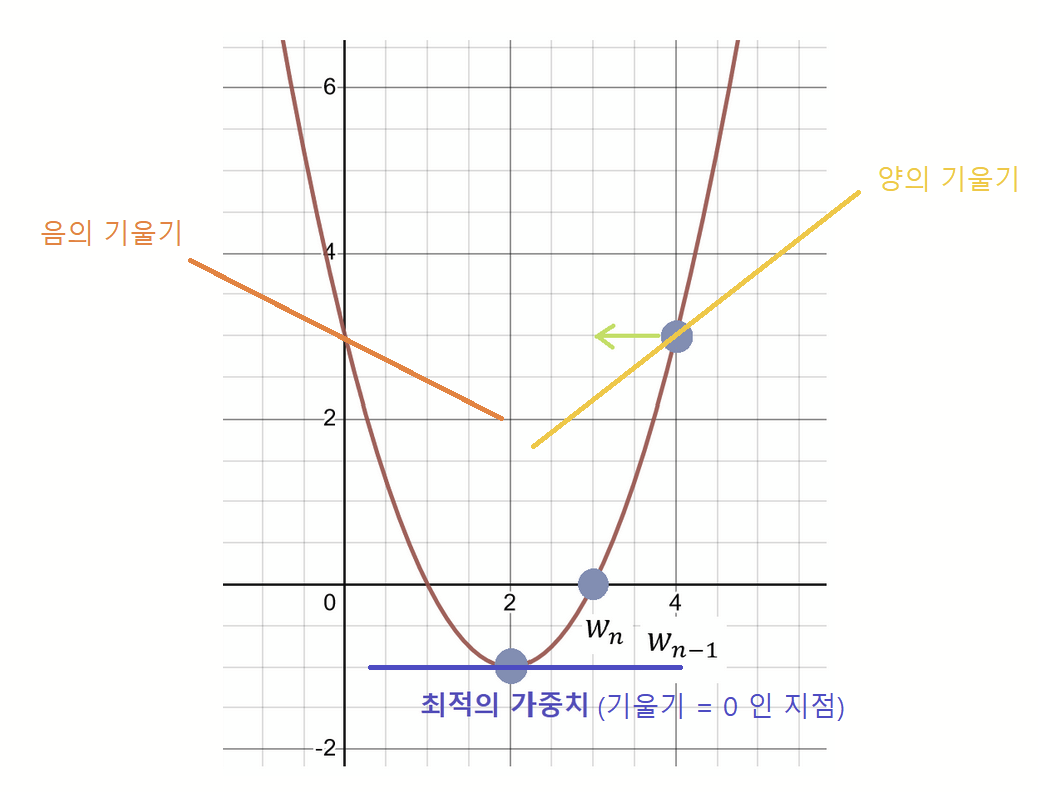
x가 4인 지점에서의 접선을 보면 양의 기울기를 가지고 있다. 기울기가 0인 지점을 찾는 것이 최종 목표이니 기울기의 값이 0이 되게 -방향으로 가야 하며 x가 0인 지점에선 음의 기울기를 가지고 있으니 +방향으로 가야 최적지점에 도달하는 것이다. 그래서 경사하강법에서 미분값의 -만큼 빼주는 값으로(즉, 미분값의 반대방향으로) 가중치를 업데이트하는 것이다.
편미분

식을 보면 변수 x1와 x2 이렇게 두개를 가지고 있다. 2개의 변수를 가지고 있으므로 도함수도 2차원이 된다. 이런 미분을 편미분이라 한다. 편미분은 어렵게 생각하지 말고, 그냥 각각 변수에 대해 독립적으로 미분하면 된다. (한 변수로 미분 시 나머지 변수를 상수취급하면 되는 것) 편미분의 결과는 벡터 형태로, 이 벡터를 Gradient 라고 한다.
편미분을 이용하면 다차원의 공간에서 최저점을 찾을 수 있다. 두 변수의 도함수를 0으로 하는 그 해를 구하면 된다.
경사 하강법(Gradient Descent)
경사 하강법은 머신러닝/딥러닝에서 사용되는 최적화 방법 중 하나이다. 학습 시 우리의 목표는 손실 함수(Loss Function)의 값을 최소화하는 파라미터[가중치(weight)와 편향(bias)] 를 구하는 것이다. 최적의 편향값과 최적의 가중치값을 경사 하강법을 통해 구할 수 있다.

위의 함수는 가로축은 가중치(w)를, 세로축은 손실 함수(Loss function)를 의미한다. 먼저 임의의 가중치를 하나 선정한다. 운이 매우 좋다면 최솟값에 해당되는 가중치를 한번에 선택할 수도 있지만, 그렇지 않을 확률이 훨씬 높은 법이다. 임의의 가중치가 w_(n-1) 이라 하자. (이 가중치가 시작점이 되는 것이다.) 목적함수를 해당 점(w_(n-1))에 대해 편미분을 한 후, 이를 학습률(Learning rate) 과 곱한다. 이 값을 w_(n-1) 에서 빼주면 된다.
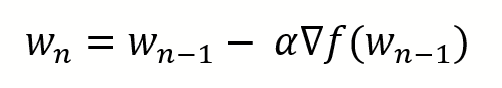
개선된 해가 발생하지 않을 때까지, 가중치의 값을 업데이트하는 과정을 반복한다. 이렇게 값이 가장 낮은 지점으로(최솟값) 경사를 타고 하강하는 기법이어서 경사 하강법이라고 부른다.
(개선된 해가 더 이상 발생하지 않는다는 것은 최적의 값을 찾았다는 것이다. 이는 최적의 해에 도달했다는 것으로 미분값이 0 이 되었다는 뜻이다. 미분값이 0이 니 개선된 값에서 0을 몇번이고 빼봤자 그대로다. 값이 그대로이니 더 이상 개선될 수가 없게 된다.)

앞서 설명한 최적화 방법은 배치 경사 하강 알고리즘(Batch Gradient Descent)이다. 이 알고리즘에선 훈련집합X 에 있는 모든 샘플에 대한 Gradient 를 계산한 다음, 평균화 한 후 한꺼번에 매개변수를 갱신한다. (그래서 배치 Batch라는 단어가 이름에 들어간다. Batch 는 집단, 무리라는 뜻을 가지고 있다.) 아무튼, 이는 많은 연산량을 요구해서 한 번에 샘플 하나의 Gradient를 계산하자는 확률적 경사하강법 (Stochastic Gradient Descent)이 제안되었다. Gradient 를 계산하고 바로 매개변수를 변경하는 일을 모든 샘플에 수행하면 한 세대(Epoch)이 지났다고 말한다.
학습률(Learning Rate)

학습률이란 어떤 비율만큼 파라미터를 업데이트할지를 결정하는 값으로, 즉 이동량을 조절하는 값이다. (얼마만큼 이동해야 최적해에 도달한느지 알 수 없으므로) 학습률은 0과 1 사이의 값을 가진다. 보통 0.001과 같이 작은 값의 학습률을 이용한다. 학습률은 사용자가 지정해줘야 하는 하이퍼파라미터(Hyper-parameter)다. 이 학습률을 설정하는 것도 중요하다. 너무 작은 값으로 학습률을 설정할시, 수렴이 너무 늦어진다. 그렇다고 또 너무 큰 값을 주면 함수 자체를 벗어나거나 최적해에서 더 멀어져버리는 등의 경우가 생길 수도 있어서, 적절한 학습률을 선택하는 것이 중요하다.
(학습률은 매번 바꿔줄 필요없이 한 번만 입력해주면 된다. 어차피 파라미터가 업데이트 되가면서 미분값이 작아져 처음 지정해줬던 같은 학습률이 곱해져도 보폭이 줄어들기 때문이다.)
참고
책: Maschine Learning 기계학습 | 한빛아카데미 | 오일석
https://daebaq27.tistory.com/35
https://heytech.tistory.com/380
https://m.blog.naver.com/sqlmvp/221855713144
'인공지능 > Machine & Deep Learning' 카테고리의 다른 글
| 배치 사이즈(batch size) | 에포크(epoch) | 반복(iteration) 차이 (2) | 2023.04.18 |
|---|---|
| 손실함수(Loss function) (0) | 2023.04.13 |
| 다층 퍼셉트론(MLP: Multi Layer Perceptron)과 활성화 함수(Activation function) (0) | 2023.04.12 |
| 인공신경망(ANN: Artificial Neural Network)과 퍼셉트론(Perceptrons) (0) | 2023.04.11 |
| 인공신경망(Neural Network) (0) | 2023.04.04 |