해당 내용은 책 Maschine Learning 기계학습 (한빛아카데미 | 오일석) 을 요약 및 정리한 글입니다.
머신러닝에 대해서 좀 더 깊이 알아보자.
기계 학습 개념
아래 예시를 통해 기계 학습의 개념을 알아보도록 하자. 아래 그래프에서 가로축은 시간이고 세로축은 물체의 이동한 위치다. 물론 다른 여러 상황이 될 수도 있고. 2초, 4초, 6초 점을 샘플링해 물체의 이동 위치를 측정한 결과, 3.0, 4.0, 5.0, 6.0 이렇게 4개의 값을 얻었다고 가정 시, 이때 임의의 시간에 대한 물체의 위치를 예측하는 문제를 풀어야 한다.

기계학습은 이러한 예측(Prediction) 문제를 푸는 것이며, 이 예측 문제는 회귀(Regression)와 분류(Classification)로 나뉜다. 위에 예시처럼 실숫값을 예측하는 경우 회귀라 하며 숫자 인식 같은 문제는 10가지의 부류 중 하나의 숫자를 예측하는 문제로 분류라고 한다. 숫자 인식 문제를 그래프로 표현한다면 입력값인 가로축이 입력패턴이 될 것이고, 세로축은 패턴이 가져야 될 목표값(target value)이 된다.
기계학습에선 가로축에 해당하는 패턴을 특징(Feature)이라 한다. 위 예시에서는 특징이 하나뿐이나 보통 2개 이상의 특징으로 구성되는 특징벡터 형태를 띠므로 특징은 스칼라가 아닌 벡터 표기를 사용해야 한다. 따라서 훈련집합(Training Set)는 아래 처럼 표기하며 훈련집한의 요소를 사례 또는 샘플이라 부른다.
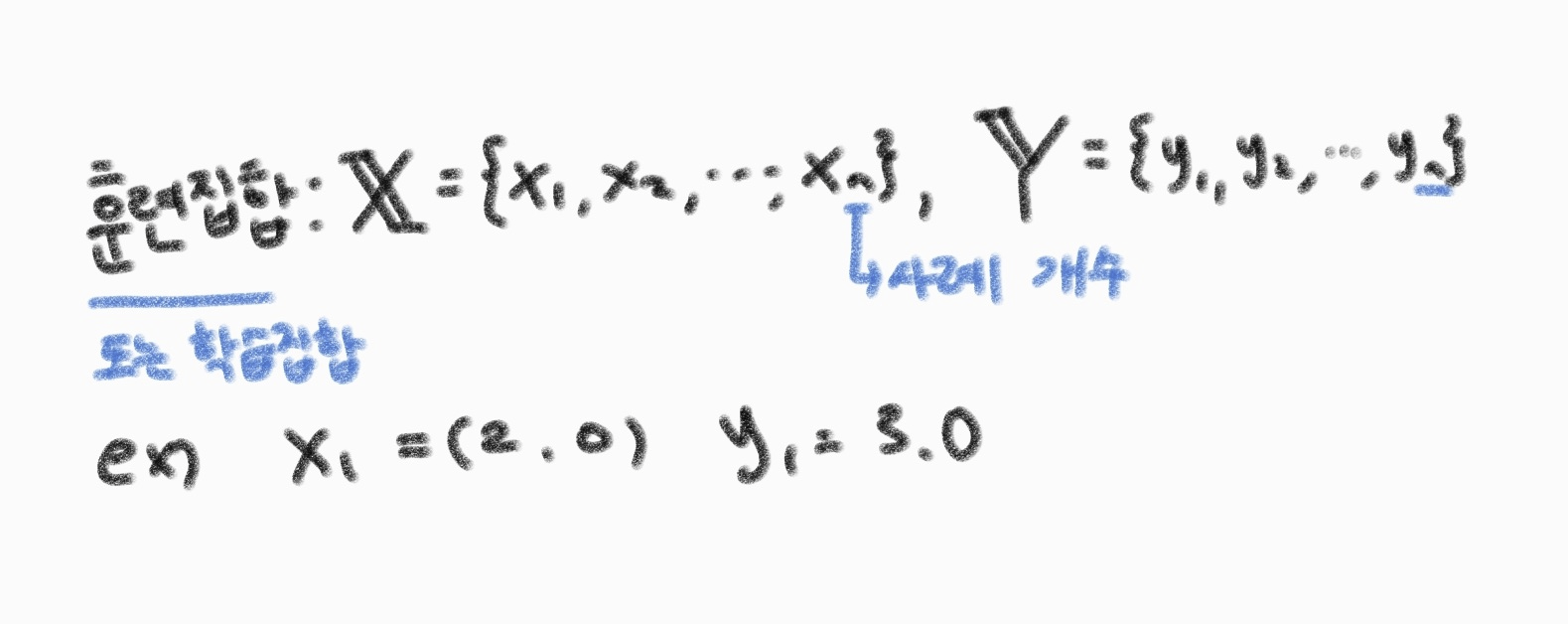
위의 예시는 직선이므로 y = wx + b 와 같이 2개의 매개변수를 가진 식으로 표현할 수 있다. 기계학습이란 가장 정확히 예측할 수 있는, 최적의 매개변숫값을 찾는 작업이다. 이 문제에선 w = 0.5, b =2.0 이 최적의 매개변수로 그래프속 f3이 해당된다.
처음 최적의 매개변수값을 알 수 없어 임의의 값을 설정해 f1이 되었다가 점차 최적의 상테인 f3에 도달했다면, 모델이 성능을 점차 개선하여 최적의 상태에 도달했다고 얘기할 수 있으며, 이를 학습(Learning) 또는 훈련(Training) 이라고 한다.
학습과정이 끝나면 학습된 모델을 이용한 예측이 가능하다. 예를 들어 60.0 이라는 시간에서의 물체의 위치를 알고 싶다면 f3(70.0) = 0.5 * 70.0 + 2.0 = 37.0 의 값을 출력할 수 있다. 이와 같이 훈련집합에는 없는 새로운 샘플에 대한 목표값을 예측하는 하나의 과정을 테스트라고 한다. (새로운 샘플을 가진 데이터는 테스트 집합 | Test set 이라 함.)
이처럼 기계는 사람이 준비한 데이터를 입력 받아, 수학을 사용해 최적의 매개변숫값을 찾아가는 학습을 한다.
기계학습의 최종 목표 : 훈련집합에 없는 새로운 샘플에 대한 오류를 최소화하는 것.
기계학습을 좀 더 쉽게 이해하기 위해 예시를 가져왔다.
아래 내용은 유튜브 채널 '코딩애플'의 쉬운 딥러닝 강의를 정리한 글입니다. (⇓ 강의링크)
https://www.youtube.com/watch?v=U57LVkQVf4o
기계학습이란?
이 사진을 보고 사람인지 아닌지 판단해야 하는 문제가 있다고 해보자.
기계도 사람처럼 모종의 알고리즘을 통해 눈, 코,입 등을 인지 후 사람이라고 판단할 것이다.
그 알고리즘은 사람이 입력해 줄수도 있은나 그 알고리즘을 기계가 스스로 학습하게 만드는 것이 머신러닝이다.
즉, 수많은 사람의 사진들을 보여주면서 학습하게 하는 것.
적용 사례
스팸 메일을 자동 분류하는 AI를 만든다고 가정해보자.
예전에 사람이 직접 알고리즘을 만들 당시엔, 메일 제목에 광고나 할인 등이 들어가면 스팸으로 분류하라는 단순한 알고리즘만이 가능했다.
머신러닝은 몇만개의 스팸메일을 분석하면서 어떤 글자가 포함되어있으면 스팸메일일 확률이 높은지 스스로 알아서 알고리즘을 짠다.
그렇담, 어떻게 학습하는가?
간단한 예로 학생의 모의고사 점수를 토대로 수능 성적을 예측해야 한다고 가정해보자.

기계학습 전에 사람으로서 한번 예측해보자.

각 모의고사 성적이 수능 성적에 50%씩 영향을 미춘다고 가정해 수능성적을 계산하였다. 이 계산을 수식으로 표현한다면 매개변수 두개(w1,w2)를 사용해 표현할 수 있을 것이다. 하지만 내가 예상한 이 0.5 라는 값은 부정확할 확률이 높으니 기계한테 w1,w2의 값을 알아서 찾은 후 그 결과값을 예측하게 시키는 게 머신러닝이다.
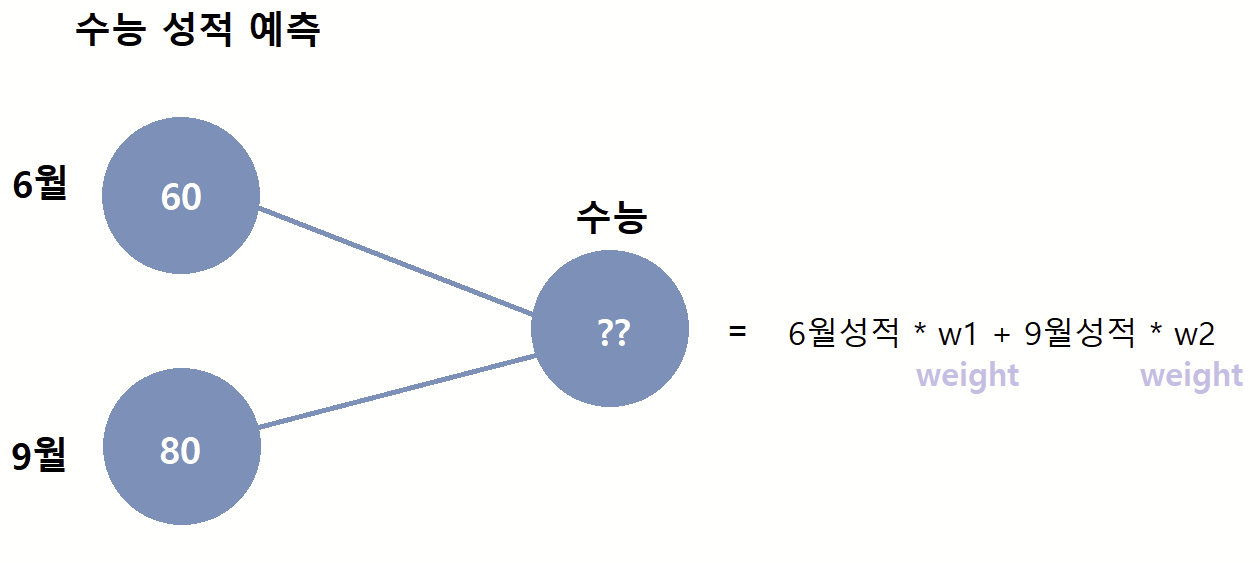
이 매개변수 w의 정확한 명칭은 weight 로 가중치를 뜻한다. "6월 성적과 9월 성적이 어느정도의 가중치를 가지고 있는가?" 를 표현하기 위한 미지수이다. 즉, 위에서처럼 0.5의 가중치를 줬다면 6월 성적이 수능 성적에 50%의 영향력을 끼친다는 뜻
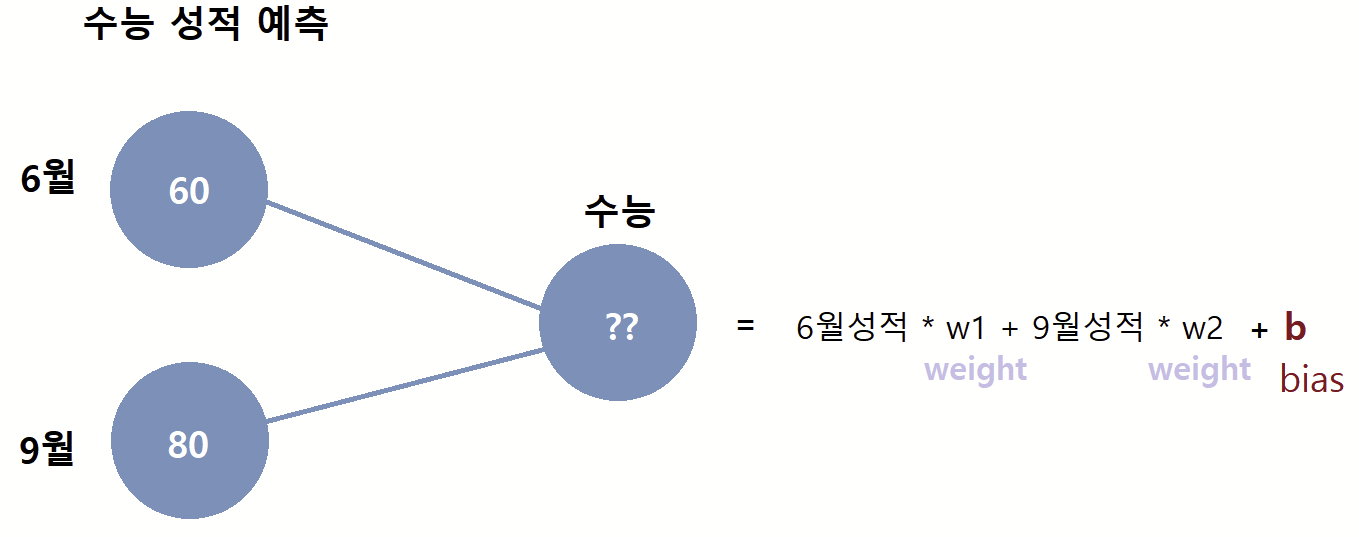
일반적으로 수식에 매개변수 'b'를 더한다. 수능성적에 영향을 끼치는 요소가 6월과 9월 모의고사 성적 외에도 해당년도 수능의 난이도라던가 가산점 등이 존재할 수 있기 때문이다. 이런 b라는 상수도 같이 예측해줘야하는 경우들이 보통인데 이 상수 b는 bias '편향' 이라고 불린다. 편향 b를 더해줌으로서 더욱 정교한 모델이 된다.
w1과 w2값을 컴퓨터에게 예측하라고 시켜야하는데, 이 때 기준이 필요하다. 최대한 정확하게 예측할수 있도록 시키려면 컴퓨터에게 데이터를 가져다 줘야한다. 여기선 여러 학생의 6월, 9월 모의고사와 수능 성적 데이터를 주는 것.
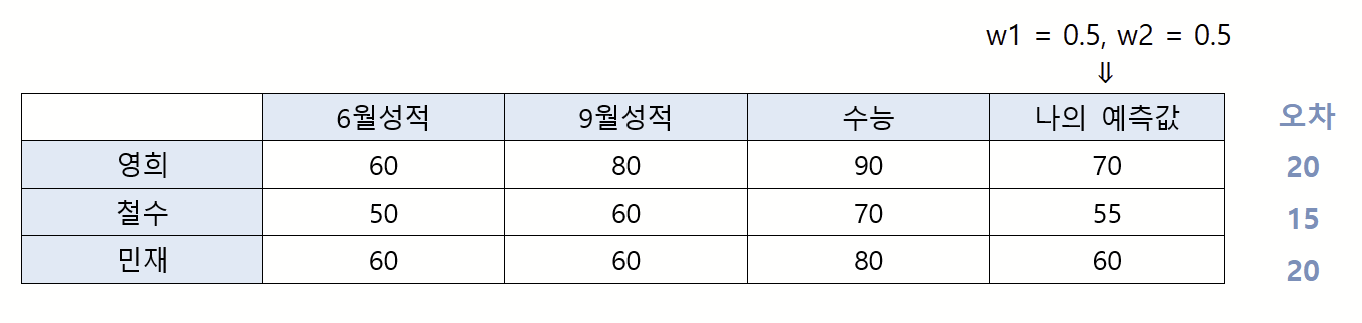
학생들의 실제 데이터를 나의 모델에서 얻은 값과 비교해 보았다. 실제 수능점수와 내가 예측한 수능 성적의 값을 보면 차이남을 볼 수 있다. (이 오차값을 평가하는 함수들도 있다.) 이 오차값을 최소화 시키는 방향으로 매개변수 w의 값을 수정해가는게 컴퓨터가 해야할 작업이다.
'인공지능 > Machine & Deep Learning' 카테고리의 다른 글
| 다층 퍼셉트론(MLP: Multi Layer Perceptron)과 활성화 함수(Activation function) (0) | 2023.04.12 |
|---|---|
| 인공신경망(ANN: Artificial Neural Network)과 퍼셉트론(Perceptrons) (0) | 2023.04.11 |
| 인공신경망(Neural Network) (0) | 2023.04.04 |
| Machine Learning 유형: 지도 | 비지도 | 강화 학습 (0) | 2023.04.04 |
| Machine Learning 기계학습이란? (0) | 2023.04.02 |