가구나 프라모델을 조립해야한다고 가정해보자.
이 때, 조립방식도 조립을 시작하게 되는 접근 방법도 다양할 것이다.
설명서가 있다면 설명서대로 따라서 조립하면 될 것이고, 이미 어떻게 조립하는지 스스로 알고 있다면 설명서 없이 조립하면 될 것이다. 하지만 설명서를 읽어도 도통 모르겠거나 알고있는 기본적인 조립방법 또한 알지 못하는 상태라면, 가구나 프라모델의 부품을 어떻게 조립하는지는 조립하는 사람에게 달려있다.
머신러닝도 마찬가지다. 연구하는 과제와 이용할 수 있는 데이터의 종류에 따라 이에 적합한 학습 모델을 사용해 알고리즘을 학습시키도록 한다. 여기서 알고리즘을 학습 시키는 방법은 위의 가구조립 예처럼 다양한 방식이 존재한다.
이 방식에는 크게 지도 방식에 따라 4가지 유형으로 나뉜다.
지도 학습 | Supervised learning
"문제와 정답을 모두 알려주고 공부시키는 방법"
: 완전히 '분류'가 된 데이터셋이 주어짐(명시적인 정답 즉 레이블이(label)이 주어진다는 뜻).
이 말은 다시 말해서, 입력(특징 백터)과 출력(목푯값) 이렇게 쌍으로 데이터가 주어지는 경우를 말한다.
출력이 이러한다는 정보를 알려준다 해서 '지도'라는 명칭이 사용된다.
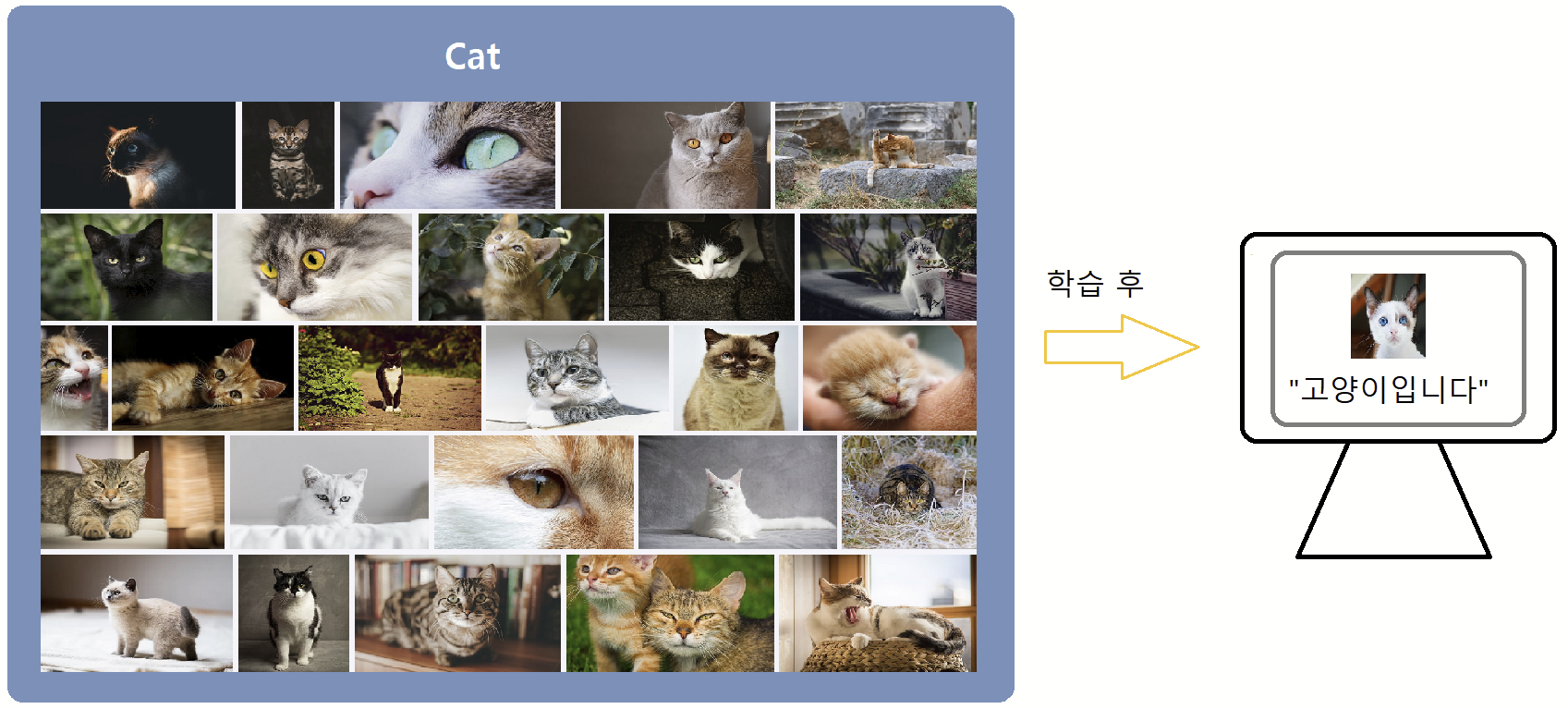
고양이를 인식하게 인공지능을 가르친다고 할 때, 고양이가 어떤 건지 수많은 고양이의 사진(고양이라는 라벨이 붙여진)을 주며 학습시킨다. 학습이 완료되면 사전에 학습을 위해 주었던 고양이 사진(training set)이 아닌 다른 새로운 사진을 보여주어 이 사진이 고양이인지를 맞추게 한다.
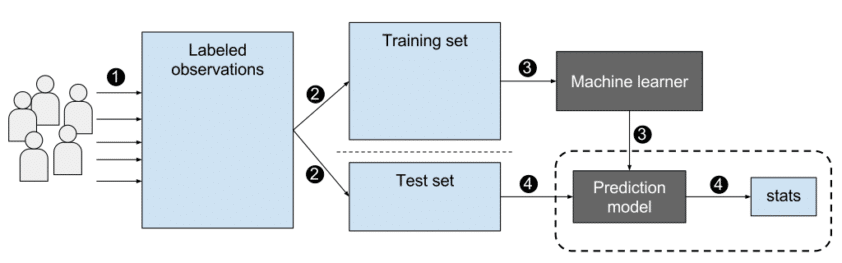
Training set : 학습 할 때 주어지는 데이터로 학습집합(learning set) 또는 훈련집합(training set)라 한다.
Test set : 새로운 샘플을 가진 데이터
지도 학습의 알고리즘 유형
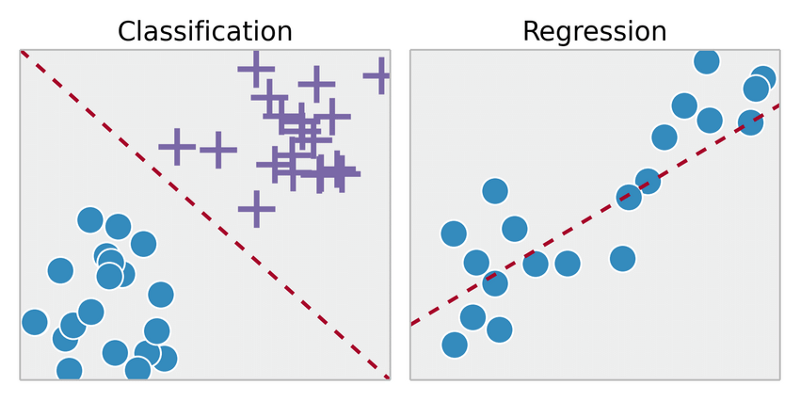
지도 학습으로 해결이 가능한 문제는 분류(Classification) 와 회귀(Regression) 이렇게 두가지로 나뉜다.
1. 분류(Classification)
출력이 몇가지의 부류로 주어질 때
[예시]
Haberman survival 데이터베이스
: 유방암 환자의 데이터(나이,수술년도,양성림프샘개수)^T 를 통해 환자의 수술 후 생존연수 예측 (5년 이내로 사망하는가 / 5년 이상 생존하는가)

MNIST 데이터베이스
: 사람들의 필기 숫자 데이터 제공 (0 ~ 9까지의 숫자 중 어떤 숫자인지 맞추기)

IRIS 붓꽃 데이터베이스
: (꽃받침의 길이, 꽃받침 너비, 꽃잎 길이, 꽃잎 너비)^T 데이터 제공 (setosa, versicolor, virginica 중 붓꽃의 품종은 무엇인가)
2. 회귀(Regression)
출력이 연속된 실수(continuous value)로 주어질 때
"특정 x값이 주어졌을 때, 변수 y의 기대값은 무엇인가?"
[예시]
- 면적에 따른 집의 가격 예측 이라던가 평수, 위치, 대중 교통 근접성에 따른 서울의 아파트 가격을 예측 등
- 대량의 중고차 판매 데이터에서 연식, 주행거리, 브랜드 등을 사용하여 중고차 가격 예측
비지도 학습 | Unsupervised learning
"답을 가르쳐주지 않고 공부시키는 방법"
완벽하게 깔끔히 분류된 데이터 세트는 구하기 쉽지 않다. 또한 사람들은 때때로 자신들조차 모르는 문제를 물어야 할 때도 존재한다. 이렇게 비지도 학습이 시작된다.
비지도 학습에서는 명확한 지시가 없이 데이터(레이블이 주어지지 않은) 세트가 주어진다.
이 데이터 세트는 구체적인 희망하는 결과나 올바른 답이 없는 예시들의 모음으로 컴퓨터는 이 데이터 세트에서 유용한 특징을 추출하고 구조를 분석하려 노력한다.
비지도 학습의 알고리즘 유형
1. 군집화(Clustering)
"특정 기준에 따라 유사한 데이터 사례들을 하나의 세트로 그룹화하는 것"

분류되지 않은 탈 것 사진 데이터를 준다면 비슷해보이는 데이터끼리 찾아 그룹으로 만들어 분류해준다.
그 외: 영화를 비슷한 장르끼리 묶어준다거나 방문횟수나 사용금액에 따른 백화점 고객 분류 등
2. 이상 탐지(Anomaly detection)
"평소와 다른 특이점(ex.평소와 다른 패턴, 평소와 다른 값)을 찾아내는 것"
은행은 고객의 구매 행동에서 특이한 패턴을 발견 시 사기거래를 탐지하게 된다. 예로, 한 신용카드가 각각 미국 캘리포니아와 덴마크에서 같은 날 사용됐다면, 그건 의혹의 원인이 된다. 이와 유사하게, 자율 학습은 데이터 세트에 특정 값을 표시하는데 쓰일 수 있다. 이외에도 주식 사기 거래 감지, 비정상 세포감지 등에도 사용되고 있다.
3. 연상(Association)
온라인 장바구니에 기저귀, 애기 양말, 빨대 컵등을 넣었다면 사이트가 저절로 턱받이 등 다른 아이용품을 추천해준다.
이건 하나의 연상의 예시인데, 바로 데이터 샘플의 어떤 특성을 다른 특성과 연관 짓는 것이다. 데이터 포인트의 핵심 속성을 몇 개 파악함으로써, 자율 학습 모델은 연관된 다른 속성들을 예측할 수 있다.
강화 학습 | Reinforcement learning
"보상 및 벌칙과 함께 여러 번의 시행착오를 거쳐 스스로 학습하는 방법"

강화학습은 일종의 게임처럼 생각하면 된다. 예시로 벽돌깨기 게임을 가져왔다. 게임 내에선 보상(벽돌을 깨면 +5점!)과 벌칙(벽돌을 떨어트리면 -8점!)이 존재한다. 그럼 컴퓨터는 이리저리 파란색 막대를 움직여가며 최종 점수가 가장 높게끔 스스로 학습한다.
가장 유명한 대표적인 사례로 알파고가 있다.
준지도 학습 | Semi-supervised learning
"지도 학습과 비지도 학습을 섞어서 정답을 유추해 나가는 방법"
데이터를 수집하는 일은 비용이 많이 들기도 하고 정답인 목푯값(레이블)을 부여하는 일도 사람이 직접 수행해야 하니 많은 비용이 든다. 준지도 학습은 소량의 데이터만 부류정보를 부여 후, 이 소량의 데이터와 부류 정보가 존재하지 않는 대량의 데이터를 함께 활용해 성능 향상을 모색하는 것이다.
참고
https://blogs.nvidia.co.kr/2018/09/03/supervised-unsupervised-learning/
https://www.youtube.com/watch?v=U57LVkQVf4o
https://box-world.tistory.com/5
https://modulabs.co.kr/blog/machine-learning/
https://live.lge.co.kr/live_with_ai_01/
책: Maschine Learning 기계학습 | 한빛아카데미 | 오일석
'인공지능 > Machine & Deep Learning' 카테고리의 다른 글
| 다층 퍼셉트론(MLP: Multi Layer Perceptron)과 활성화 함수(Activation function) (0) | 2023.04.12 |
|---|---|
| 인공신경망(ANN: Artificial Neural Network)과 퍼셉트론(Perceptrons) (0) | 2023.04.11 |
| 인공신경망(Neural Network) (0) | 2023.04.04 |
| Machine Learning 기계 학습 개념 (0) | 2023.04.03 |
| Machine Learning 기계학습이란? (0) | 2023.04.02 |



